Convolutional Neural Networks (CNNs)
Convolutional Neural Networks (CNNs) are variants of deep neural networks that have been applied successfully to the problems of Object Classification and Detection over the past decade[7]. The basic architecture of a CNN is outlined below:
Figure 2. Diagrammatic representation of typical Convolutional Neural Network architecture. Click for image source

To learn more about each layer in a CNN, click the bold text:
Input Layer
The input layer takes in the RGB intensity values of an image. In the above figure a 36x36 image with three colour channels is depicted [8].
Convolutional Layer
The Convolutional layer applies a kernel convolution to the input image. This is a mathematical transform in which a scrolling window of weights (known as the Kernel) is applied to each pixel in the input image. The corresponding pixel in the output image is computed as the dot product of all intensity values covered by the window and their corresponding weights (figure 3) [8].

Figure 3. Animation of convolution. Scrolling window (blue) applied to Original image (green) to produce output image (yellow) in accordance with kernel weights (striped). Click for image source
In a CNN, Kernel weights are randomly initialised and then optimised (via backpropagation) to highlight relevant features in the network.
Pooling Layer
The output of the convolutional layer is downsampled through a transformation known as pooling. There are many variants of pooling - the most common being Max Pooling (Figure 4) [8].
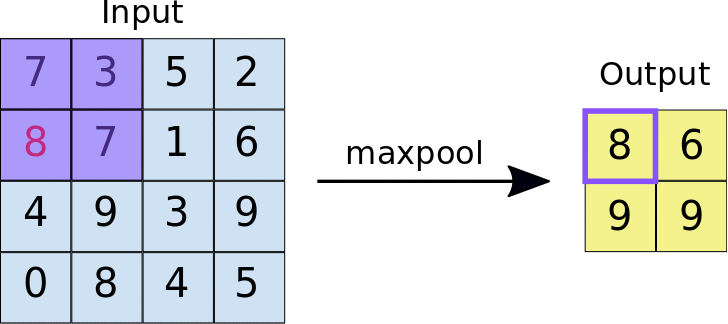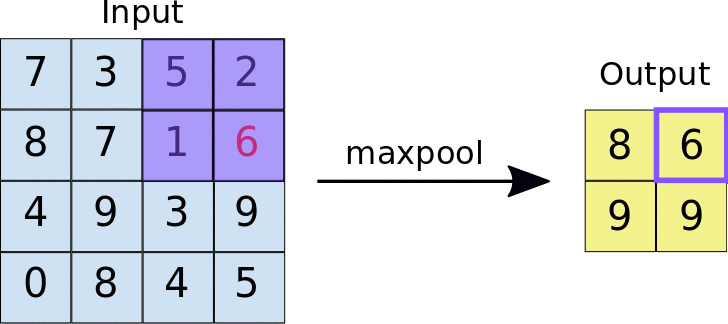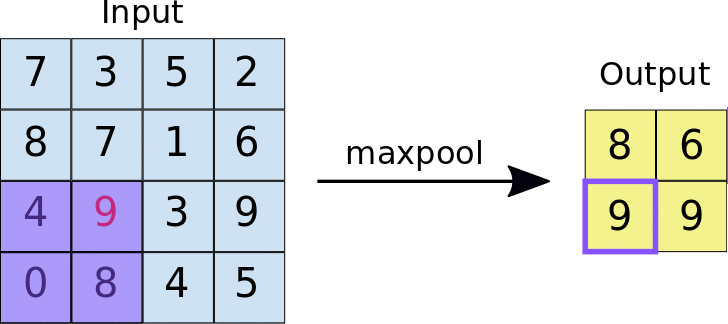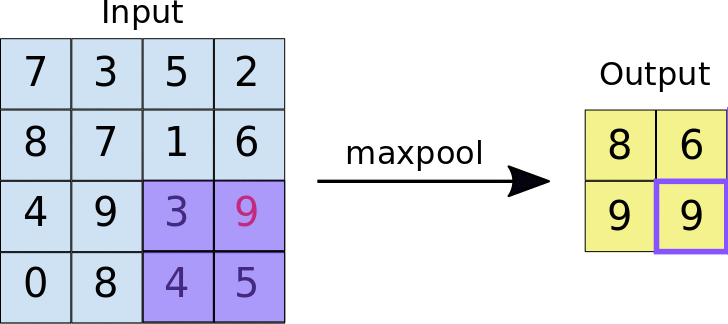
Figure 4. Animation of Max Pooling. A Scrolling 2x2 window is applied to the input image, returning the largest intensity value to create a downsampled output image. Click for image source
Fully Connected Layer
This layer resembles a more traditional neural network architecture - here the intensity values for each of the final downsampled images are fully connected to a layer of neurons (all with associated weights and biases) [8].
Output Layer
The last fully connected layer is linked to output neurons corresponding to object classes [8].
As the network is trained on a series of input images with associated class labels, both the weights of the kernels and the neurons are optimised to give the best classification [8].
An intuitive interactive demonstration of Object Classification using a CNN to detect handwritten numbers can be found here, where each layer in the network is fully visualised [9].
Extending Object Classification to Object Detection
The above implementation only explains how CNNs can be used to classify images. For the problem of object detection (where the location and number of objects matter) the architecture must be adapted.
Faster R-CNN
Faster R-CNN finds relevant subsections of an image by proposing regions of interest within the image that are likely to contain the object, and investigating each with a classifier similar to the one depicted above [3].
Proposals are generated by first passing an input image through several convolutional layers to generate a feature map. A separate region proposal network RPN passes over this feature map returning bounding box coordinates for potential objects[3].
YOLOv4
YOLO (You Only Look Once) takes a more unified approach to object detection computing both bounding box regression and classification with a single convolutional network. This provides faster inference times, however the object notably struggles to detect smaller objects in frame[4].